What is Supertonic TTS?
Supertonic TTS is a fast, on-device text-to-speech system built for performance with minimal computational overhead. This system runs entirely on your device using ONNX Runtime, meaning no cloud services, no API calls, and no privacy concerns. Everything happens locally, giving you complete control over your data and instant speech generation.
The system is designed to generate speech at speeds up to 167 times faster than real-time on consumer hardware like the M4 Pro. With only 66 million parameters, Supertonic TTS maintains a small footprint while delivering natural-sounding speech output. The model handles complex text inputs including numbers, dates, currency, abbreviations, and technical expressions without requiring pre-processing or special formatting.
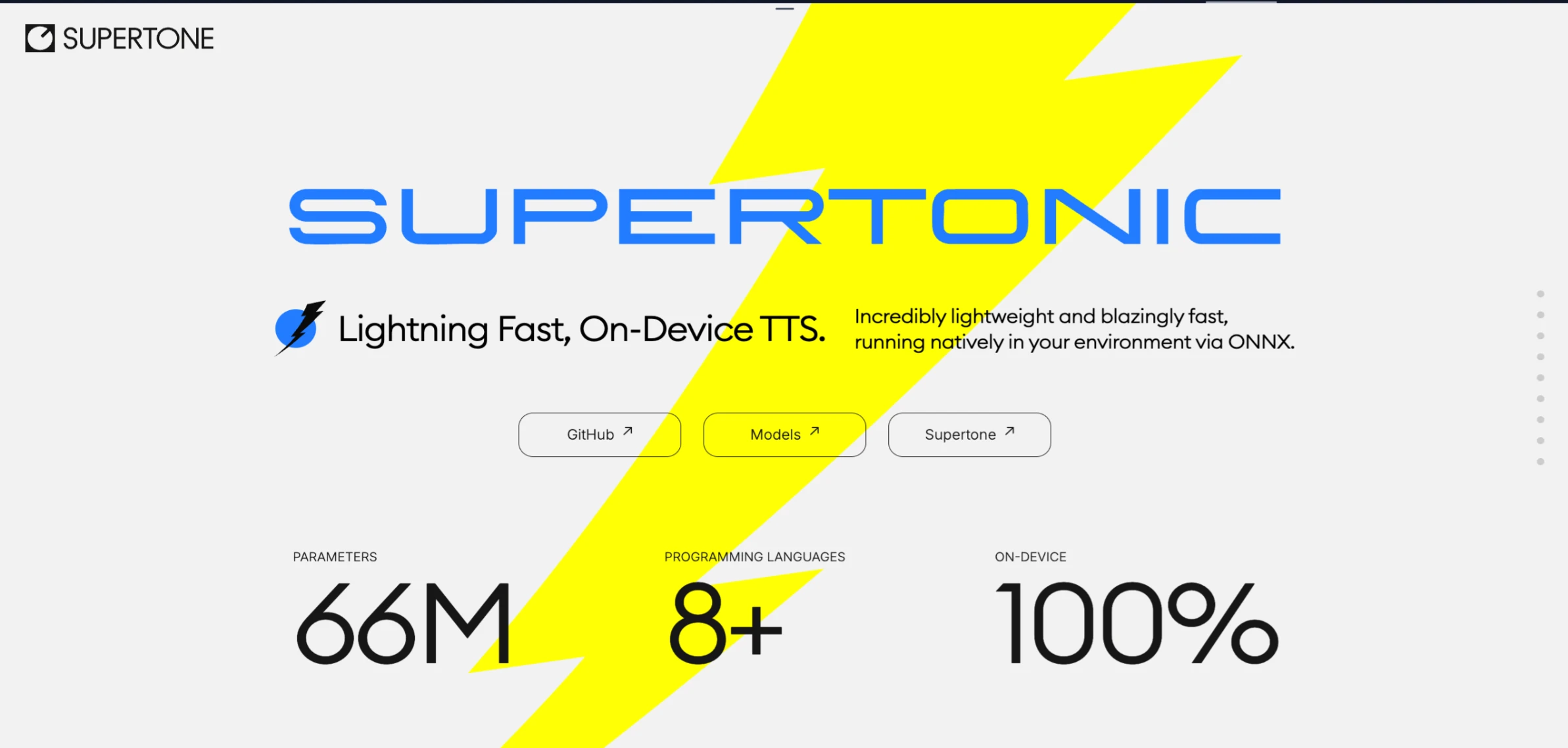
Supertonic TTS works across multiple platforms and programming languages. You can deploy it on servers, in web browsers, or on edge devices. The system supports Python, Node.js, Java, C++, C#, Go, Swift, iOS, Rust, and Flutter, making it accessible to developers working in different environments.
Overview of Supertonic TTS
| Feature | Description |
|---|---|
| System Type | On-Device Text-to-Speech |
| Runtime | ONNX Runtime |
| Model Size | 66 Million Parameters |
| Speed | Up to 167x Real-Time |
| Privacy | Complete On-Device Processing |
| Platform Support | Python, Node.js, Java, C++, C#, Go, Swift, iOS, Rust, Flutter |
| Audio Output | 16-bit WAV Files |
Key Features of Supertonic TTS
Fast Performance
Supertonic TTS generates speech up to 167 times faster than real-time on consumer hardware like the M4 Pro. This speed advantage makes it suitable for real-time applications where quick response times are essential.
Small Model Size
With only 66 million parameters, Supertonic TTS maintains a compact footprint. This small size makes it practical for deployment on devices with limited storage or memory, including mobile devices and embedded systems.
Complete Privacy
All processing happens locally on your device. There are no cloud connections, no data transmission, and no external API calls. Your text and generated audio never leave your device, ensuring complete privacy and security.
Natural Text Handling
The system processes complex text inputs naturally. It handles numbers, dates, currency symbols, abbreviations, and technical expressions without requiring pre-processing. You can input text as you would write it, and Supertonic TTS will pronounce it correctly.
Configurable Settings
You can adjust inference steps, batch processing, and other parameters to match your specific needs. This flexibility allows you to balance speed and quality based on your requirements.
Cross-Platform Support
Supertonic TTS works across multiple platforms and programming languages. Whether you are building a web application, mobile app, or desktop software, you can integrate Supertonic TTS into your project.
Zero Latency
Since all processing happens on-device, there is no network latency. Speech generation begins immediately when you provide text input, making it ideal for interactive applications.
Try Supertonic TTS
Experience Supertonic TTS in your browser with our interactive demo. Enter text and hear it spoken instantly using on-device processing.
Performance Metrics
Supertonic TTS has been evaluated using two key metrics: characters per second and real-time factor. These measurements show how the system performs across different text lengths and hardware configurations.
On an M4 Pro with CPU processing, Supertonic TTS achieves 912 to 1263 characters per second depending on text length. With WebGPU acceleration, performance increases to 996 to 2509 characters per second. On high-end hardware like the RTX 4090, the system reaches 2615 to 12164 characters per second.
The real-time factor measures how long it takes to generate audio relative to its duration. Lower values mean faster generation. Supertonic TTS achieves real-time factors as low as 0.005 on RTX 4090, 0.012 on M4 Pro CPU, and 0.006 on M4 Pro with WebGPU. This means the system can generate audio much faster than it would take to play it back.
When compared to cloud-based API services, Supertonic TTS shows significant speed advantages. Cloud services typically achieve 12 to 287 characters per second, while Supertonic TTS on consumer hardware reaches over 1000 characters per second. This performance difference makes on-device processing a practical choice for many applications.
Natural Text Handling
Supertonic TTS is designed to handle real-world text inputs that contain various types of information. The system processes financial expressions, time and date formats, phone numbers, and technical units without requiring special formatting or pre-processing.
Financial expressions with decimal currency, abbreviated magnitudes like M and K, currency symbols, and currency codes are pronounced correctly. Time and date formats including time notation, abbreviated weekdays and months, and various date formats are handled naturally. Phone numbers with area codes, hyphens, and extensions are spoken in a clear, understandable way.
Technical units with decimal numbers and abbreviated notations are processed accurately. This capability means you can input text as you would normally write it, without worrying about special formatting rules or phonetic annotations.
Language and Platform Support
Supertonic TTS provides ready-to-use inference examples across multiple programming languages and platforms. Each implementation includes detailed usage instructions in the respective README files.
Python developers can use the ONNX Runtime inference implementation. Node.js developers have access to server-side JavaScript examples. Browser-based applications can use WebGPU or WASM inference for client-side processing. Java developers can integrate Supertonic TTS into JVM-based applications.
C++ implementations provide high-performance options for native applications. C# developers can use the .NET ecosystem integration. Go, Swift, iOS, Rust, and Flutter implementations offer additional deployment options for various application types.
Use Cases for Supertonic TTS
Supertonic TTS is suitable for a wide range of applications where fast, private, on-device speech synthesis is needed. The system works well for accessibility features, allowing applications to read text aloud for users who benefit from audio output.
Interactive applications can use Supertonic TTS to provide voice feedback without network delays. Educational software can generate speech for reading exercises or language learning tools. Productivity applications can convert documents to speech for listening while multitasking.
Mobile applications benefit from on-device processing, as it works without internet connectivity and preserves user privacy. Embedded systems and IoT devices can integrate Supertonic TTS for voice output capabilities. Gaming applications can use the system for dynamic dialogue generation or narration.
Content creation tools can generate voiceovers for videos or podcasts. Assistive technology devices can provide text-to-speech functionality for users with visual impairments. Navigation systems can announce directions and information without relying on cloud services.
Technical Details
Supertonic TTS uses ONNX Runtime for cross-platform inference. The system is optimized for CPU processing, though GPU acceleration is available in some configurations. Browser support is provided through onnxruntime-web for client-side inference.
The system supports batch processing for improved throughput when generating multiple audio outputs. Audio is output as 16-bit WAV files, providing good quality while maintaining reasonable file sizes. The model architecture includes a speech autoencoder, flow-matching based text-to-latent module, and efficient design choices that enable fast inference.
Supertonic TTS uses Length-Aware Rotary Position Embedding (LARoPE) to improve text-speech alignment in cross-attention mechanisms. The training process includes self-purification techniques for training flow matching models with reliable labels.
Pros and Cons
Pros
- Fast speech generation up to 167x real-time
- Complete privacy with on-device processing
- No internet connection required
- Handles complex text inputs naturally
- Small model size at 66 million parameters
- Cross-platform support for multiple languages
- Zero latency for instant speech generation
- Configurable settings for different use cases
Cons
- Requires local storage for model files
- Performance varies with hardware capabilities
- Initial setup requires downloading model files
- Limited to supported languages and voices
- GPU acceleration not tested in all configurations
Getting Started with Supertonic TTS
To get started with Supertonic TTS, you need to clone the repository and download the ONNX models and preset voices. The models are stored using Git LFS, so you will need to install and initialize Git LFS before cloning.
Once you have the repository and models, you can choose the implementation that matches your programming language or platform. Each implementation includes example code that demonstrates how to use Supertonic TTS for text-to-speech conversion.
The system is designed to be straightforward to integrate into existing projects. The example code shows the basic workflow: load the model, provide text input, and receive audio output. You can then customize the settings to match your specific requirements.
For detailed installation and usage instructions, visit the Installation page or refer to the README files in each language directory. The documentation includes step-by-step guides for setting up Supertonic TTS in different environments.